Organizations
Resources
Introduction
Organizations can subscribe to hardware resources to run backtests, launch research notebooks, and deploy live trading algorithms to co-located servers. Organizations also have access to storage resources via the Object Store to store data between backtests or live trading deployments. To promote efficiency, all of these resources within your organization are shared among all of the members within the organization. A team of several quants can all share one backtest, research, and live trading node.
Backtesting Nodes
Backtesting nodes enable you to run backtests. The more backtesting nodes your organization has, the more concurrent backtests that you can run. Several models of backtesting nodes are available. Backtesting nodes that are more powerful can run faster backtests and backtest nodes with more RAM can handle more memory-intensive operations like training machine learning models, processing Options data, and managing large universes. The following table shows the specifications of the backtesting node models:
| Name | Number of Cores | Processing Speed (GHz) | RAM (GB) | GPU |
|---|---|---|---|---|
| B-MICRO | 2 | 3 | 8 | 0 |
| B2-8 | 2 | 4.9 | 8 | 0 |
| B4-12 | 4 | 4.9 | 12 | 0 |
| B4-16-GPU | 4 | 3 | 16 | 1/3 |
| B8-16 | 8 | 4.9 | 16 | 0 |
Refer to the Pricing page to see the price of each backtesting node model. You get one free B-MICRO backtesting node in your first organization. This node incurs a 20-second delay when you launch backtests, but the delay is removed and the node is replaced when you subscribe to a new backtesting node in the organization.
By default, the best-performing resource is selected when you run a backtest, but you can select a specific resource to use.
GPU nodes perform best on repetitive and highly-parallel tasks like training machine learning models. It takes time to transfer the data to the GPU for computation, so if your algorithm doesn't train machine learning models, the extra time it takes to transfer the data can make it appear that GPU nodes run slower than CPU nodes.
You can't use backtesting nodes for optimizations. The CPU nodes are available on a fair usage basis. The GPU nodes can be shared with a maximum of three members. Depending on the server load, you may use the all of the GPU's processing power.
Research Nodes
Research nodes enable you to use the Jupyter Research Environment. Several models of research nodes are available. More powerful research nodes allow you to handle more data and run faster computations in your notebooks. The following table shows the specifications of the research node models:
| Name | Number of Cores | Processing Speed (GHz) | RAM (GB) | GPU |
|---|---|---|---|---|
| R1-4 | 1 | 2.4 | 4 | 0 |
| R2-8 | 2 | 2.4 | 8 | 0 |
| R4-12 | 4 | 2.4 | 12 | 0 |
| R4-16-GPU | 4 | 3 | 16 | 1/3 |
| R8-16 | 8 | 2.4 | 16 | 0 |
Refer to the Pricing page to see the price of each research node model. You get one free R1-4 research node in your first organization, but the node is replaced when you subscribe to a new research node in the organization.
By default, the best-performing resource is selected when you launch a research notebook, but you can select a specific resource to use.
The CPU nodes are available on a fair usage basis. The GPU nodes can be shared with a maximum of three members. Depending on the server load, you may use all of the GPU's processing power.
Live Trading Nodes
Live trading nodes enable you to deploy live algorithms to our professionally-managed, co-located servers. Several models of live trading nodes are available. More powerful live trading nodes allow you to run algorithms with larger universes and give you more time for machine learning training. Each security subscription requires about 5MB of RAM. The following table shows the specifications of the live trading node models:
| Name | Number of Cores | Processing Speed (GHz) | RAM (GB) | GPU |
|---|---|---|---|---|
| L-MICRO | 1 | 2.6 | 0.5 | 0 |
| L1-1 | 1 | 2.6 | 1 | 0 |
| L1-2 | 1 | 2.6 | 2 | 0 |
| L2-4 | 2 | 2.6 | 4 | 0 |
| L8-16-GPU | 8 | 3.1 | 16 | 1/2 |
Refer to the Pricing page to see the price of each live trading node model.
By default, the best-performing resource is selected when you deply a live algorithm, but you can select a specific resource to use.
GPU nodes perform best on repetitive and highly-parallel tasks like training machine learning models. It takes time to transfer the data to the GPU for computation, so if your algorithm doesn't train machine learning models, the extra time it takes to transfer the data can make it appear that GPU nodes run slower than CPU nodes.
The CPU nodes are available on a fair usage basis. The GPU nodes can be shared with a maximum of two members. Depending on the server load, you may use the all of the GPU's processing power.
Sharing Resources
Your organization's nodes are shared among all of the organization's members to reduce the amount of time that nodes idle. In the Algorithm Lab, you can see which nodes are available within your organization.
Training Quotas
Algorithms normally must return from the OnData method within 10 minutes, but the Train method lets you increase this amount of time. Training resources are allocated with a leaky bucket algorithm where you can use a maximum of n-minutes in a single training session and the number of minutes available refills over time. This gives you a reservoir of training time when you need it and recharges the reservoir to prepare for the next training session. The reservoir only starts draining after you exceed the standard 10 minutes of training time.
The following animation demonstrates the leaky bucket algorithm. The tap continuously adds water to the bucket. When the bucket is full, water spills over the rim of the bucket. The water represents your training resources. When your algorithm exceeds the 10 minutes of training time, holes open at the bottom of the bucket and water begins to drain out. When your algorithm stops training, the holes close and the bucket fills up with water.
.gif)
The following table shows the amount of extra time that each backtesting and live trading node can spend training machine learning models:
| Model | Capacity (min) | Refill Rate (min/day) |
|---|---|---|
| B-MICRO | 20 | 1 |
| B2-8 | 30 | 5 |
| B4-12 | 60 | 10 |
| B8-16 | 90 | 15 |
| L-MICRO | 30 | 5 |
| L1-1 | 60 | 10 |
| L1-2 | 90 | 15 |
| L1-4 | 120 | 20 |
The refill rate in the table above is based on the real-world clock time, not the backtest clock time. In backtests, the Train method is synchronous, so it will block your algorithm from executing while the model is trained. In live trading, the method runs asynchronously, so ensure your model is ready to use before you continue executing the algorithm. Training occurs on a separate thread, so use a semaphore to track the model state.
Log Quotas
Per our Terms and Conditions, you may not use the logs to export dataset information. The following table shows the amount of logs each organization tier can produce:
| Tier | Logs Per Backtest | Logs Per Day |
|---|---|---|
| Free | 10KB | 3MB |
| Quant Researcher | 100KB | 3MB |
| Team | 1MB | 10MB |
| Trading Firm | 5MB | 50MB |
| Institution | Inf. | Inf. |
To check the log storage space you have remaining, log in to the Algorithm Lab and then, in the left navigation bar, click Organization > Resources.
If you delete a backtest or project that produced logs, your quotas aren't restored. Additionally, daily log quotas aren't fully restored at midnight. They are restored according to a 24-hour rolling window.
The log files of each live trading project can store up to 100,000 lines for up to one year. If you log more than 100,000 lines or some lines become older than one year, we remove the oldest lines in the files so your project stays within the quota.
To avoid reaching the limits, we recommend logging sparsely, focusing on the change events instead of logging every time loop. You can use the debugger to inspect objects during runtime. If you use the debugger, you should rarely reach the log limits.
Coding Session Quotas
If you have a project open, it uses a coding session. Paid organizations can have multiple active coding sessions, but free users can only have one coding session open at a time. The following table shows how many active coding sessions you can have on each organization tier:
| Tier | Initial Coding Session Quota |
|---|---|
| Quant Researcher | 2 |
| Team | 4 |
| Trading Firm | 8 |
| Institution | 16 |
If the organization you're in has more live trading nodes than your initial coding session quota, then your coding session quota increases to the number of live trading nodes you have in the organization so you can view all your live strategies.
The quota for free organizations is a global quota, so you can have one active coding session across all of your free organizations. The quotas for paid organizations are at the organization level. Therefore, if you are in two Quant Researcher organizations, you can have two active coding sessions in one of those organizations and another two active sessions in the other organization. These paid tier quotas are for each account, not for the organization as a whole. For instance, a Trading Firm organization can have more than eight members and all of the members can simultaneously work on projects within the organization.
Live Trading Notification Quotas
The number of Telegram, email, or webhook notifications you can send in each live algorithm for free depends on the teir of your organization. The following table shows the hourly quotas:
| Teir | Number of Notifications Per Hour |
|---|---|
| Free | N/A |
| Quant Researcher | 20 |
| Team | 60 |
| Trading Firm | 240 |
| Institution | 3,600 |
If you exceed the hourly quota, each additional Telegram, email, or webhook notification costs 1 QuantConnect Credit (QCC).
Each SMS notification you send to a US or Canadian phone number costs 1 QCC. Each SMS notification you send to an international phone number costs 10 QCC.
View All Nodes
The Resources page displays your backtesting, research, and live trading node clusters. To view the page, log in to the Algorithm Lab and then, in the left navigation bar, click Organization > Resources.
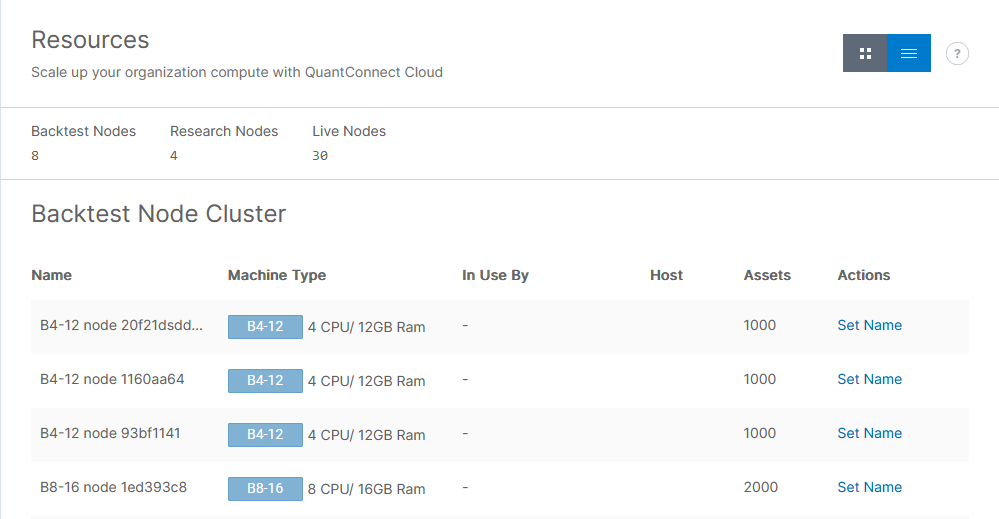
To toggle the format of the page, click the buttons in the top-right. If the page is in table view, each cluster section includes a table with the following columns:
| Column | Description |
|---|---|
| Name | Name of the node |
| Machine Type | The node model and specifications |
| In Use By | The name of the member using the node |
| Host | The live trading server name |
| Assets | The recommended maximum number of assets to avoid RAM errors. |
| Actions | A list of possible actions |
Add Nodes
You need billing permissions in the organization to add nodes.
Follow these steps to add nodes to your organization:
- Open the Resources page.
- Click for the type of node you want to add.
- Select the node specifications.
- Click .
The Resources page displays the new node.
Remove Nodes
You need billing permissions in the organization to remove nodes. If you remove nodes during your billing period, your organization will receive a pro-rated credit on your account, which is applied to future invoices.
Follow these steps to remove nodes from your organization:
- Log in to the Algorithm Lab.
- In the left navigation bar, click Organization > Home.
- On the organization homepage, click .
- Click the Customize Plan > Build Your Own Pack > Compute Nodes tab.
- Click the minus sign next to the node model you want to remove.
- Click .
Rename Nodes
We assign a default name to hardware nodes that includes the model name and an arbitrary string of characters, but you can follow these steps to rename the nodes in your organization:
- Open the Resources page.
- Click on the node that you want to rename.
- Enter the new node name and then click .
The Resources page displays the new node name.
Stop Nodes
You need stop node permissions in the organization to stop nodes other members are using. If you stop a node, it terminates the running backtest, research, or live trading sessions. When you stop a live trading node, the portfolio holdings don't change but the algorithm stops executing.
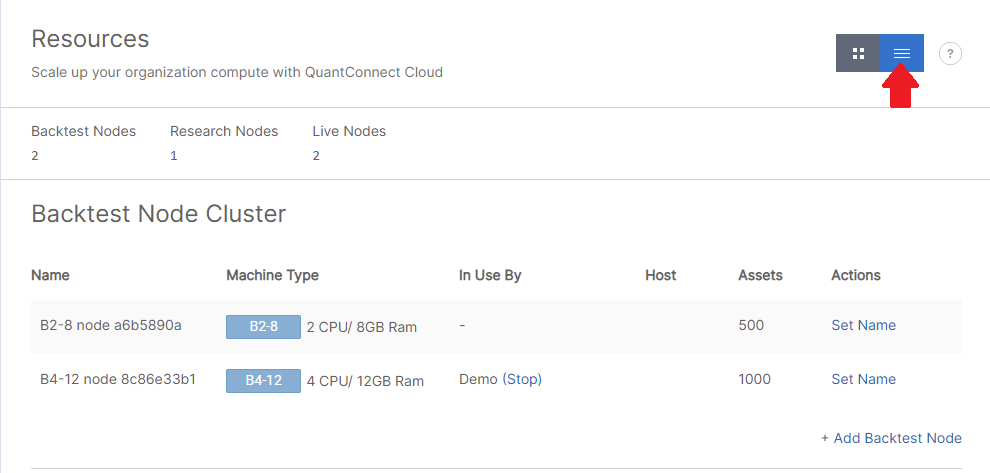
Follow these steps to stop nodes that are running in your organization:
- Open the Resources page.
- Click the icon with the three horizontal lines icon in the top-right corner to format the page into table view.
- Click in the row with the node that you want to stop.
You can also see our Videos. You can also get in touch with us via Discord.
Did you find this page helpful?