




As a fan of machine learning for trading I am always on the lookout for tricks and ways to improve the performance of my algorithms. In this regard I have been playing for a while with the concept of Meta-Labeling in the hope of squeezing additional returns out of my trading models.
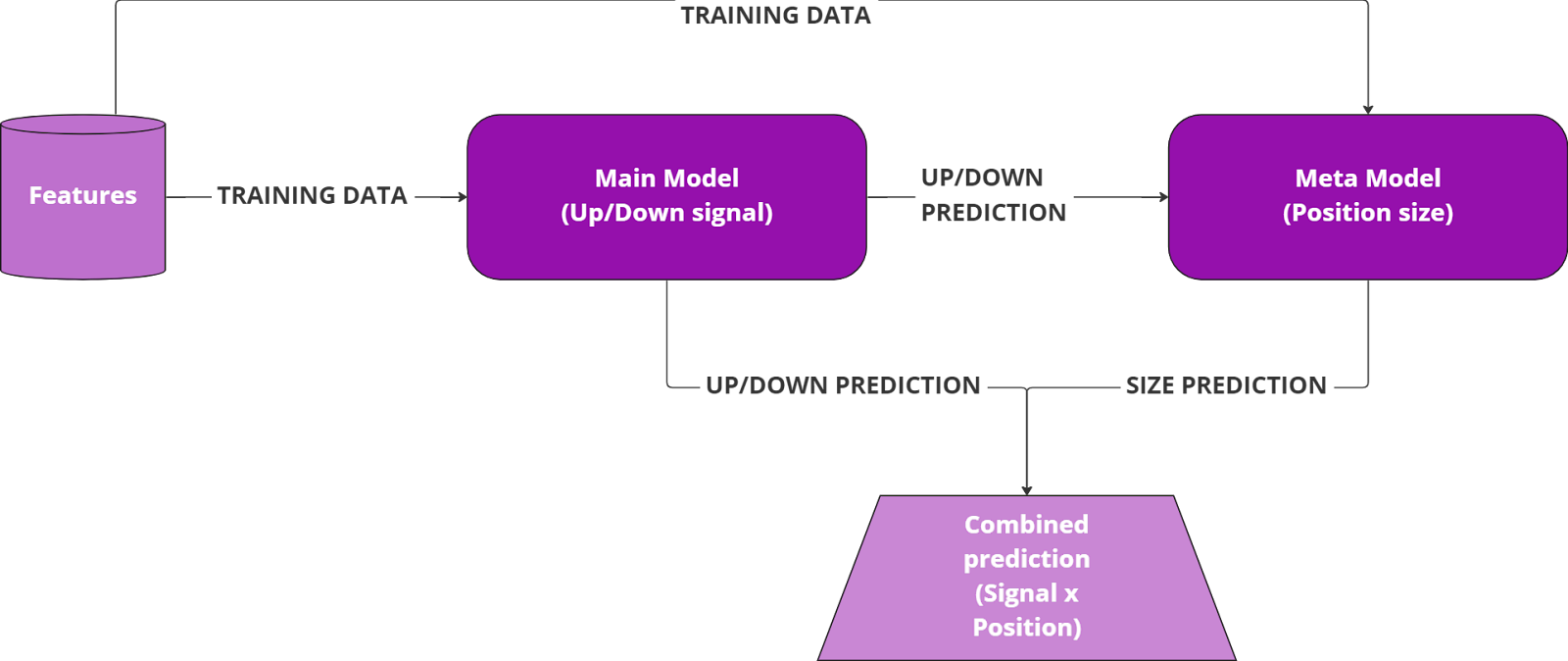
High level structure of a meta-labeling algorithm
By Meta-Labeling I refer to a technique introduced by Marcos Lopez de Prado in his book Advances in Financial Machine Learning to systematically address the issue of sizing the position of trades, or signals, generated by another model (the “main” one). At a high level the technique works as follow:
- Have a main model generating the signal or direction of a trade. This model can be a ML model or a discretionary one;
- Train a secondary machine learning model, the meta model, that takes the main model features (if present), its predictions and is trained to predict whether the first main model was correct or not
- Feed the main model predictions in the meta model so that you can estimate the likelihood of the main model (the signal) to be correct and use this secondary prediction to decide whether to trade or not and size the position to be taken.
The idea is very interesting and I believe has some specific fields of application but, I argue, it is not a panacea that is able to magically improve the performance of a machine learning model that has access to the same data. For instance, in this article by Hudson & Thames (which I follow and generally like) they argue that Meta-Labeling is a general purpose technique that can improve the performance of Machine Learning models.
What I argue, according to my experience and to pure logic, is that this technique can only improve the performance of existing discretionary trading models but cannot improve the performance of a main Machine Learning model trained end-to-end on the same data.
I outline here the reasons and will also attach a simple experiment proving my point:
- To improve the performance of the main ML model the meta model should be able, somehow, to extract more information from the existing features than the main model does. There is no logical reason for which the meta model should find more information in the data than the main one;
- If cascading a meta-model after a main one was actually able to improve the overall trading performance then there is no reason to stop there; we could add a meta-meta-model trained on the meta-model predictions and continue like this ad-infinitum;
- Having a meta model correctly sizing the trades, or signals, is as difficult as having a model generating the right signals. If you imagine having a naive buy-and-hold main model, i.e. signal always equal to 1, then the burden of the performance would be completely on the meta-model which would need to decide if and how much to buy. I wish I had such a meta-model to tell me how much exposure to take in SPY!
I attach here a simple algorithm using machine learning on simple technical features to either:
- Train a single, main-model, end-to-end and use the predicted probability of a profitable trade as the position size (parameter “use_meta” equal to 0)
- Train a main model on the trade direction and use a second, meta-model prediction to size the position to be taken (parameter “use_meta” equal to 1)

Comparison of algorithm with and without Meta-Labelling
I ran several simulations through a grid search varying only the parameter “use_meta” and you can see that, while the range of performance widens, the meta-model is not able to squeeze additional returns compared with a single end-to-end model (average sharpe ratio is lower).

Grid search with use_meta 0/1 over multiple seeds
To conclude I believe the merits of this technique are highlighting the importance of sizing properly a bet and providing a way to do that for existing discretionary models but I argue that it cannot increase the performance of a Machine Learning model trained end-to-end.
If you experimented with the same topic and you have similar or opposing views on the topic I’d be happy to know more!
Francescowww.beawai.com








MichaelMeyer01
Hi Francesco,
This is an interesting discussion and I have a few suggestions that might make the model better.
Let me know if you disagree with this or not, I would be happy to discuss if further!
Also here is a link to a paper that explains it a bit better.
Francesco Baldisserri
Hi Michael,
Thanks for your comments, they are very interesting. Indeed the example is little more than a toy algorithm although I believe it is still enough to highlight some grey areas of meta-labeling.
Regarding your suggestions here's my comments/questions to make sure I understood them properly:
Thanks again for the comments. Happy to continue the conversation anytime!
Francesco
P.S, Thanks for the paper referral. I stumbled on it already although I don't have that subscription!
Lars Klawitter
hi Francesco,
thanks a lot for your post. I too have been playing around with de Prado's meta labeling concept, specifically using H&T's MLFinlab library.
I tried meta labeling on top of an already reasonably well performing ExtraTreesClassifier trading logic (shout out to Cole S, who's algorithm I expanded upon) but wouldn't get any improvement out of it - just the opposite, the algo performed significantly worse than without the meta model.
So your suggestion that ML can hardly be optimised as no new information is added makes sense to me.
Looking at your implementation, I realise I might have some issues in my implementation to begin with, e.g. I did not train the two models on separate sets like you do, so I'll have to think about information leakage a bit more.
I might have another go a meta labeling, picking up Michael's point #3 of using market state information for the meta model (although I hear you - why not give this bit of information to the primary model to begin with…)
Francesco Baldisserri
Hi Lars,
Thanks for your comment. I agree with your points and happy that it was an input for you to review your own meta-labeling implementation. Indeed, as Michael pointed out, my implementation is far from perfect and it captures only the high level “spirit” of this technique.
My whole position on this topic can be summed up as “You cannot squeeze the same orange twice”; in other words you can't use the same data (i.e. the “orange”) to train 2 models and there is no reason to me for which two cascaded models would do better than a single one trained on the whole data. I see instead the point of using a ML-based model for sizing the positions when the signal is not generated using that market data (i.e. for a discretionary technique).
Indeed I think you should use strictly separate datasets for main and meta model training otherwise the latter would be over-confident given that the main model would have an unreasonably high accuracy.
Let me know how your experiment go!
Axist
I might be missing understanding of how you described meta labeling, essentially ML to test the accuracy or successfulness of your indicators. In the above example, you used ML to test a previous ML algorithim that was indicating buy/sell signals, but you mentioned this could be used
How might one go about combining the meta-labeling concept mentioned here with something like the popular In-Out algorithm? Or something that looks at Key Economic indicators to navigate through Late, Decline, Rebound, Early market cycles?
Or starting something more basic, say I wanted to use the concept here to evaluate the indicators of my Technical Analysis, something that does:
Can the concept you're describing above “fine tune” when you should actually act on a “buySignal” or “sellSignal” executing? Or affect the sizing in which the buy order or sell order is executed?
Francesco Baldisserri
Hi Axist,
Indeed the meta-labeling objective is to have a brake/accelerator for your trading signals, whether they are ML generated or not.
This ML meta-model would be trained on the features or, in the case of a discretionary strategy, the buying signals used (e.g. MACD) and correlate them with the actual performance of the signal. This second signal coming from the meta-model can be used to switch on or off your trading signals (similar to the In and Out in a sense) or size the position according to the risk.
In the example that you mention I would, assuming that you want to use a meta-model, train a ML model on the buying signals, SMA in this case, plus any other feature you want to add to be able to predict the probability of your signals of being correct. You can then use these predictions to size your trading positions accordingly instead of statically as it is done now.
My thesis is that the meta-model makes more sense where the underlying signal is not ML generated and would benefit from a ML layer so this case is actually a good one.
I hope it was helpful and let me know if you are trying it out!
Francesco
Adam W
Francesco Baldisserri
Late to the discussion as I've been away from QC, but great post and I do overall agree that meta-labeling is not some magic tool and has the most benefit when the first-stage/primary model is simple (i.e. a linear model or a discretionary strategy as you pointed out). However, I would not entirely dismiss its usefulness even when the first-stage model is a flexible ML model.
For example, consider a flexible neural network as first-stage model that makes predictions for returns trained via mean-squared error. One potential application of the meta-labeling idea here is to determine whether the sign of the predictions matches the true returns, which can be immensely useful. Suppose the true returns for two assets are [0.05, -0.05], then the predicted returns [-0.05, 0.05] and [0.15, -0.15] have the same MSE but the latter are clearly better estimates since it is a profitable trade vs a losing trade. A key benefit of meta-labeling IMO is that it somewhat allows for optimization of an objective that is closer to what we actually care about - which may be non-differentiable and/or too complicated to write down in closed-form.
Regarding some of your points:
Related to the example above, but I think its important to keep in mind that the optimization criteria and the purpose of the primary and meta-models are fundamentally different even if they use the same “information”.
In theory, probably. And in fact this is exactly the idea behind boosting algorithms. However even in the case where we train two models on the same dataset with the same loss function (your squeeze the same orange twice analogy), it could still have desirable properties on bias and variance. This is exactly the idea behind ensembling methods, though it is unintuitive.
This point however I completely agree with. Using a meta-model (or multiple layers of meta-models) does come at a cost by increasing model complexity, raising the risk of under/over-fitting, and can make tuning very difficult in practice. Having a poorly trained meta-model is likely worse than not having one at all.
Francesco Baldisserri
Hi Adam W,
Thanks for your comments, very insightful.
A key benefit of meta-labeling IMO is that it somewhat allows for optimization of an objective that is closer to what we actually care about - which may be non-differentiable and/or too complicated to write down in closed-form.
I find interesting the point that you make on using meta labeling for better approximating the real target or loss function. I struggle to see how you can do that at the meta-level and why you should not be able to do directly at the level 1 of the main model. Could you please elaborate on the example that you mentioned?
Thanks again on the input and please let me know if you were able to make meta-labelling work for you!
Francesco
Adam W
Sure so in that example, suppose the goal of our model is to accurately estimate returns such that it delivers a profitable trading strategy.
Let's suppose the true one-period returns for two assets (say, AAPL and SPY) at a given time are 5% and -5%. Naively optimizing for mean-squared-error in the first stage model means our estimates are close on average, but not necessarily profitable. For instance, let's say we had predicted 15% and -15% (with a MSE of 0.01) and allocate equal portfolio weights. We then realize a portfolio return of 5%. Alternatively, let's say we had predicted -5% and 5%. The MSE is still 0.01, but then we realize a portfolio return of -5%. Clearly, a single model that naively minimizes MSE has no way of discerning between these two scenarios.
So the problem then is we wish to get accurate point-estimates of returns, but also ensure the sign of the returns is correct. How do we design the model in such a case? Perhaps the simplest way may be to take some convex combination of MSE and the cross-entropy between the sign of the estimates and true returns. Of course in practice this opens up a whole bunch of potential problems in the joint optimization.
The meta-labeling approach somewhat simplifies the problem a bit, by breaking it down into a first-stage model that naively optimizes MSE, and a meta-model that estimates if the sign of the estimates are correct. This is arguably more flexible as well, since we can learn the mapping Y = m(X), and P(Y_hat = 1) = g(X) separately as two functions. There is no reason a priori to believe that m(.) and g(.) are “similar” functions in L2 space. Loosely speaking, in the one-model/joint optimization problem the gradients of the two criteria may be pulling against each other.
Hope that clarifies the example a bit. Overall though I completely agree that meta-labeling is not some magical tool and it potentially creates more problems than its worth, but it's an interesting idea. I've had some limited success where it did improve results, but the additional computational expense (especially with 30 min time limit on .Train) is tricky to get it to work.
Francesco Baldisserri
Hi Adam W,
Thanks for the explanation. Indeed you touch one of the most important topics in the use of ML for trading (and in general), which is the definition of the target and the loss function.
Indeed meta-model could be a way to approximate the actual objective function, which may be neither the MSE nor the Cross-Entropy but some combination of them. I still prefer, if that's the goal, to work on a single ML model that actually optimizes directly for my objective function.
This is the reason I personally prefer to tinker with custom loss functions as opposed to stacking models as I find it more aligned to the overall objective.
Thanks again for the valuable input!
Francesco
Francesco Baldisserri
The material on this website is provided for informational purposes only and does not constitute an offer to sell, a solicitation to buy, or a recommendation or endorsement for any security or strategy, nor does it constitute an offer to provide investment advisory services by QuantConnect. In addition, the material offers no opinion with respect to the suitability of any security or specific investment. QuantConnect makes no guarantees as to the accuracy or completeness of the views expressed in the website. The views are subject to change, and may have become unreliable for various reasons, including changes in market conditions or economic circumstances. All investments involve risk, including loss of principal. You should consult with an investment professional before making any investment decisions.
To unlock posting to the community forums please complete at least 30% of Boot Camp.
You can continue your Boot Camp training progress from the terminal. We hope to see you in the community soon!