Popular Libraries
PyTorch
Get Historical Data
Get some historical market data to train and test the model. For example, to get data for the SPY ETF during 2020 and 2021, run:
qb = QuantBook()
symbol = qb.add_equity("SPY", Resolution.DAILY).symbol
history = qb.history(symbol, datetime(2020, 1, 1), datetime(2022, 1, 1)).loc[symbol]
Prepare Data
You need some historical data to prepare the data for the model. If you have historical data, manipulate it to train and test the model. In this example, use the following features and labels:
| Data Category | Description |
|---|---|
| Features | The last 5 closing prices |
| Labels | The following day's closing price |
The following image shows the time difference between the features and labels:

Follow these steps to prepare the data:
- Perform fractional differencing on the historical data.
- Loop through the
dfDataFrame and collect the features and labels. - Convert the lists of features and labels into
numpyarrays. - Standardize the features and labels
- Split the data into training and testing periods.
df = (history['close'] * 0.5 + history['close'].diff() * 0.5)[1:]
Fractional differencing helps make the data stationary yet retains the variance information.
n_steps = 5
features = []
labels = []
for i in range(len(df)-n_steps):
features.append(df.iloc[i:i+n_steps].values)
labels.append(df.iloc[i+n_steps])
features = np.array(features) labels = np.array(labels)
X = (features - features.mean()) / features.std() y = (labels - labels.mean()) / labels.std()
X_train, X_test, y_train, y_test = train_test_split(X, y)
Train Models
You need to prepare the historical data for training before you train the model. If you have prepared the data, build and train the model. In this example, create a deep neural network with 2 hidden layers. Follow these steps to create the model:
- Define a subclass of
nn.Moduleto be the model. - Create an instance of the model and set its configuration to train on the GPU if it's available.
- Set the loss and optimization functions.
- Train the model.
In this example, use the ReLU activation function for each layer.
class NeuralNetwork(nn.Module):
# Model Structure
def __init__(self):
super(NeuralNetwork, self).__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(5, 5), # input size, output size of the layer
nn.ReLU(), # Relu non-linear transformation
nn.Linear(5, 5),
nn.ReLU(),
nn.Linear(5, 1), # Output size = 1 for regression
)
# Feed-forward training/prediction
def forward(self, x):
x = torch.from_numpy(x).float() # Convert to tensor in type float
result = self.linear_relu_stack(x)
return result
device = 'cuda' if torch.cuda.is_available() else 'cpu' model = NeuralNetwork().to(device)
In this example, use the mean squared error as the loss function and stochastic gradient descent as the optimizer.
loss_fn = nn.MSELoss() learning_rate = 0.001 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
In this example, train the model through 5 epochs.
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
# Since we're using SGD, we'll be using the size of data as batch number.
for batch, (X, y) in enumerate(zip(X_train, y_train)):
# Compute prediction and loss
pred = model(X)
real = torch.from_numpy(np.array(y).flatten()).float()
loss = loss_fn(pred, real)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch
print(f"loss: {loss:.5f} [{current:5d}/{len(X_train):5d}]")
Test Models
You need to build and train the model before you test its performance. If you have trained the model, test it on the out-of-sample data. Follow these steps to test the model:
- Predict with the testing data.
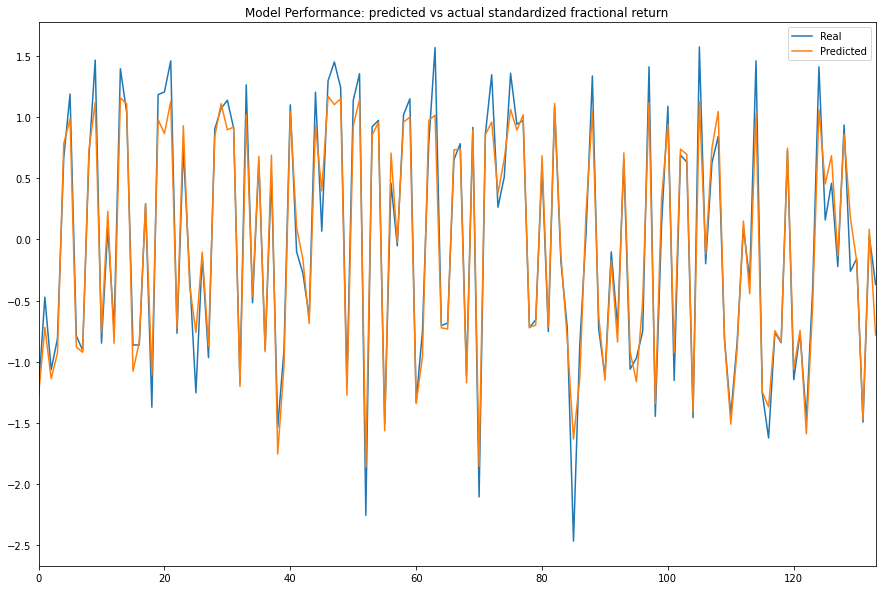
- Plot the actual and predicted values of the testing period.
- Calculate the R-square value.
predict = model(X_test) y_predict = predict.detach().numpy() # Convert tensor to numpy ndarray
df = pd.DataFrame({'Real': y_test.flatten(), 'Predicted': y_predict.flatten()})
df.plot(title='Model Performance: predicted vs actual standardized fractional return', figsize=(15, 10))
plt.show()
r2 = 1 - np.sum(np.square(y_test.flatten() - y_predict.flatten())) / np.sum(np.square(y_test.flatten() - y_test.mean()))
print(f"The explained variance by the model (r-square): {r2*100:.2f}%")

Store Models
You can save and load PyTorch models using the Object Store.
Save Models
Don't use the torch.save method to save models because the tensor data will be lost and corrupt the save. Follow these steps to save models in the Object Store:
- Set the key name of the model to be stored in the Object Store.
- Call the
GetFilePathget_file_pathmethod with the key. - Call the
dumpmethod with the model and file path.
model_key = "model"
file_name = qb.object_store.get_file_path(model_key)
This method returns the file path where the model will be stored.
joblib.dump(model, file_name)
If you dump the model using the joblib module before you save the model, you don't need to retrain the model.
Load Models
You must save a model into the Object Store before you can load it from the Object Store. If you saved a model, follow these steps to load it:
- Call the
ContainsKeycontains_keymethod. - Call the
GetFilePathget_file_pathmethod with the key. - Call the
loadmethod with the file path.
qb.object_store.contains_key(model_key)
This method returns a boolean that represents if the model_key is in the Object Store. If the Object Store does not contain the model_key, save the model using the model_key before you proceed.
file_name = qb.object_store.get_file_path(model_key)
This method returns the path where the model is stored.
loaded_model = joblib.load(file_name)
This method returns the saved model.
Examples
The following examples demonstrate some common practices for using the Pytorch library.
Example 1: Predict Next Return
The following research notebook uses Pytorch machine learning model to predict the next day's return by the previous 5 days' daily fractional differencing.
# Import the Pytorch library and others.
import torch
from torch import nn
from sklearn.model_selection import train_test_split
import joblib
# Instantiate the QuantBook for researching.
qb = QuantBook()
# Request the daily SPY history with the date range to be studied.
symbol = qb.add_equity("SPY", Resolution.DAILY).symbol
history = qb.history(symbol, datetime(2020, 1, 1), datetime(2022, 1, 1)).loc[symbol]
# Perform fractional differencing on the historical data.
df = (history['close'] * 0.5 + history['close'].diff() * 0.5)[1:]
# We use the previous 5 day fractional differencing as the features to be studied.
# Get the 1-day forward differencing as the labels for the machine to learn.
n_steps = 5
features = []
labels = []
for i in range(len(df)-n_steps):
features.append(df.iloc[i:i+n_steps].values)
labels.append(df.iloc[i+n_steps])
# Clean the data and normalize for fast convergence.
features = np.array(features)
labels = np.array(labels)
X = (features - features.mean()) / features.std()
y = (labels - labels.mean()) / labels.std()
# Split the data as a training set and test set for validation. In this example, we use 70% of the data points to train the model and test with the rest.
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Define a subclass of nn.Module to be the model. In this example, use the ReLU activation function for each layer.
class NeuralNetwork(nn.Module):
# Model Structure
def __init__(self):
super(NeuralNetwork, self).__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(5, 5), # input size, output size of the layer
nn.ReLU(), # Relu non-linear transformation
nn.Linear(5, 5),
nn.ReLU(),
nn.Linear(5, 1), # Output size = 1 for regression
)
# Feed-forward training/prediction
def forward(self, x):
x = torch.from_numpy(x).float() # Convert to tensor in type float
result = self.linear_relu_stack(x)
return result
# Create an instance of the model and set its configuration to train on the GPU if it's available.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = NeuralNetwork().to(device)
# Set the loss and optimization functions. In this example, use the mean squared error as the loss function and stochastic gradient descent as the optimizer.
loss_fn = nn.MSELoss()
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Train the model. In this example, train the model through 5 epochs.
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
# Since we're using SGD, we'll be using the size of data as batch number.
for batch, (X, y) in enumerate(zip(X_train, y_train)):
# Compute prediction and loss
pred = model(X)
real = torch.from_numpy(np.array(y).flatten()).float()
loss = loss_fn(pred, real)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch
print(f"loss: {loss:.5f} [{current:5d}/{len(X_train):5d}]")
# Predict with the testing data.
predict = model(X_test)
y_predict = predict.detach().numpy() # Convert tensor to numpy ndarray
# Plot the actual and predicted labels of the testing period.
df = pd.DataFrame({'Real': y_test.flatten(), 'Predicted': y_predict.flatten()})
df.plot(title='Model Performance: predicted vs actual standardized fractional return', figsize=(15, 10))
plt.show()
# Calculate the R-square value.
r2 = 1 - np.sum(np.square(y_test.flatten() - y_predict.flatten())) / np.sum(np.square(y_test.flatten() - y_test.mean()))
print(f"The explained variance by the model (r-square): {r2*100:.2f}%")
# Store the model in the object store to allow accessing the model in the next research session or in the algorithm for trading.
model_key = "model"
file_name = qb.object_store.get_file_path(model_key)
joblib.dump(model, file_name)
You can also see our Videos. You can also get in touch with us via Discord.
Did you find this page helpful?